aurora クラスターを lambda で 停止/開始 する方法をご紹介します。

もう、数年前になりますが、 aurora でも クラスターの 停止 ができるようになりました。
リリース前など、なるべく料金を抑えたい場合に停止しておけるのは非常に便利ですが、AWSのメンテナンスの関係で最大で7日間しか停止しておくことができません。
7日以上の停止や、恒久的に夜間は停止するなどの運用をしたい場合毎回手動で停止するのは面倒ですし事故の元です。
なんで最大7日なのか
RDSには、メンテナンスウィンドウというものがあります。
メンテナンスウィンドウは、AWSがRDSにおけるOSやDBエンジンのバージョン更新を行うためにもうけれらた時間です。
これが行われる際にRDSのリソースが起動している必要があるためです。
メンテナンスウィンドウのタイミングはRDSのコンソール画面で対象クラスターの詳細画面から確認できます。
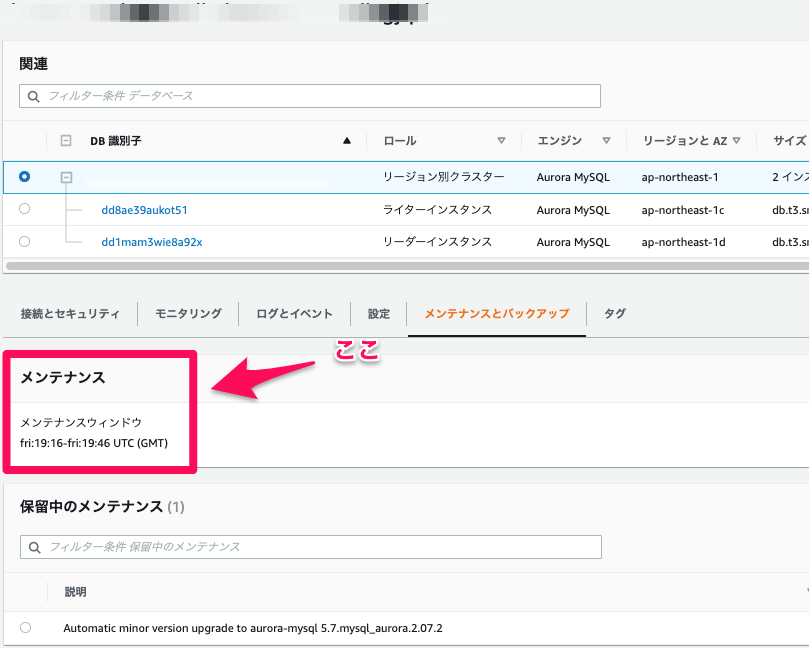
この時間帯に、起動していないとメンテナンスを受けられません。
今回は、aurora のクラスターをメンテナンス時間帯のみ起動させておけるような設定をしていきたいと思います。
CloudFormationで構築していて、完成品はgithubにあります。
githubのスクリプト実行時にはaws cliのセットアップが必要なのでこちらを参考に設定してください。
内容を解説しながらご紹介しますので、ご自身の環境にあった設定にしていただければと思います。
前提条件
今回は、RDSにauroraクラスターとインスタンスが作成済みの状態から初めていきます。
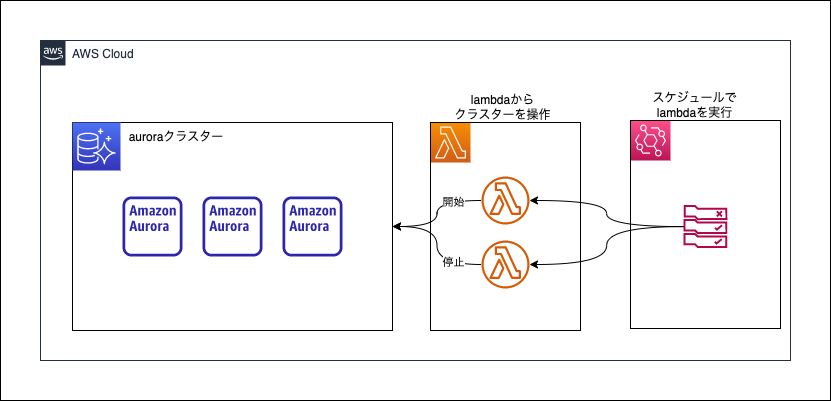
ここに、lambda関数とEventBridgeのcron式で決まったタイミングで起動/停止を行います。
テンプレートでは、lambdaとEventBridgeの部分を作成します。
RDSアクセス用のIAMロールを作成
まずは、lambdaからRDSにアクセスするために必要なロールを作成します。
テンプレート内容は以下の通り。
ここは、AWS公式がRDSインスタンスを止める時に作成したものと同じになります。
AuroraClusterControlRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Statement:
- Effect: Allow
Principal:
Service: lambda.amazonaws.com
Action: sts:AssumeRole
Policies:
- PolicyName: aurora-cluster-control-role
PolicyDocument:
Statement:
- Effect: Allow
Action:
- rds:StartDBCluster
- rds:StopDBCluster
- rds:ListTagsForResource
- rds:DescribeDBInstances
- rds:StopDBInstance
- rds:DescribeDBClusters
- rds:StartDBInstance
Resource: '*'lambda関数を作成
次に実際に停止/開始の操作を行うlambda関数を作成します。
停止と開始にそんなに差異はないので、停止の方だけ抜粋して掲載します。
大まかな処理の流れ
- クラスターの一覧を取得
- 一覧の中の利用可能なクラスターのタグをチェック
- タグに
autostop=yesが設定されていたら停止する
AuroraStopFunction:
Type: 'AWS::Lambda::Function'
Properties:
Code:
ZipFile: |
import boto3
rds = boto3.client('rds')
## クラスターの一覧を取得
clusters = rds.describe_db_clusters()
def lambda_handler(event, context):
for cluster in clusters['DBClusters']:
print (cluster['Status'])
## 取得したクラスターの中で利用可能なクラスターのみ処理
if (cluster['Status'] == 'available'):
try:
## 対象クラスターのタグを取得
GetTags=rds.list_tags_for_resource(ResourceName=cluster['DBClusterArn'])['TagList']
print(GetTags)
for tags in GetTags:
## タグにautostop=yesが含まれていれば停止する
if(tags['Key'] == 'autostop' and tags['Value'] == 'yes'):
result = rds.stop_db_cluster(DBClusterIdentifier=cluster['DBClusterIdentifier'])
print ("Stopping cluster: {0}.".format(cluster['DBClusterIdentifier']))
except Exception as e:
console.log(context.logGroupName);
console.log("Cannot stop cluster {0}.".format(cluster['DBClusterIdentifier']))
print ("Cannot stop cluster {0}.".format(cluster['DBClusterIdentifier']))
print(e)
if __name__ == "__main__":
lambda_handler(None, None)
FunctionName: aurora-stop-function
Handler: index.lambda_handler
MemorySize: 128
PackageType: Zip
ReservedConcurrentExecutions: 1
Role: !GetAtt AuroraClusterControlRole.Arn
Runtime: python3.8
Timeout: 45このlambda関数をEventBridgeでスケジュール実行すればOKです。
EventBridgeのルールを作成
先ほど作成したlambda関数をスケジュール実行するためのものになります。
こちらも、停止と開始の違いはほとんどありませんので停止のみ掲載します。
以下、コードの抜粋です。
AutoStopRule:
Type: AWS::Events::Rule
Properties:
Description: "Aurora Cluster Auto Stop Schedule"
## ここのcron式は、対象のクラスターによって変わりますので適宜変更してください。
ScheduleExpression: cron(30 11 ? * SAT *)
State: "ENABLED"
Targets:
- Arn: !GetAtt AuroraStopFunction.Arn
Id: !Ref AuroraStopFunctionスケジュールで使用しているcron式は対象のクラスターによって違ってきますので適宜変更してください。
cron式の書き方は公式で紹介されているので参考にしてください。
lambdaのトリガーを設定
lambda関数とEventBridgeのルールを作成するだけでは、lambdaをスケジュール実行することはできません。
他のサービスをlambda関数実行のトリガーにするためにはlambda側でそのリソースを許可する必要があります。
コンソール画面で言うとこの部分です。
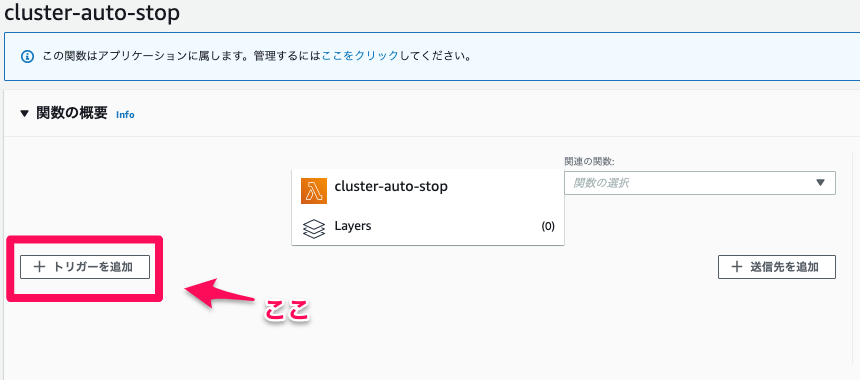
EventBridgeは先程の設定で、lambdaのトリガーになろうとしていますが、lambda側で許可していないのでトリガーに何も表示されません。
これも、停止と開始のlambda関数に設定する必要がありますが内容はほぼ同じですので停止の方だけ掲載します。
AuroraStopFunctionPermission:
Type: AWS::Lambda::Permission
Properties:
Action: lambda:InvokeFunction
FunctionName: !GetAtt AuroraStopFunction.Arn
Principal: events.amazonaws.com
SourceArn: !GetAtt AutoStopRule.Arnこれで、設定したスケジュールの通りauroraの停止が行われればOKです。
手動で試したい場合は、lambdaの画面よりテストタブから名前を入力して以下のように実行します。(JSONはからで大丈夫です。)